大模型约束解码(Constrained decoding)与结构化输出
背景
为什么要控制输出
- 结构化输出内容、模板化输出(Code, HTML, DSL, JSON, SQL)
- 多项选择
- 长度限制
- 语义约束
- 风格约束
- 避免幻觉
- 构建智能体
OpenAI 怎么做的
阶段一:JSON Mode
- GPT-4
- 提高JSON输出的可靠性
- 但并不能保证有效性
from openai import OpenAI
client = OpenAI(api_key="EMPTY", base_url="")
responses = client.chat.completions.create(
model = "",
messages = [{}],
response_format={"type": "json_object"}
logit_bias
completion = client.chat.commpletions.create(
model = "",
messages = [{}],
logit_bias = {2435:-100, 640:-100}
非确定性方法
- 借助外部工具
- 提示工程
- 反复尝试
- 打补丁
阶段二:Structured Output
- GPT-4o
- 严格匹配用户定义的JSON schemas
如何使用
- Function Calling
- response_format参数
- 支持Pydantic对象
- 结合response_format参数
from pydantic import BaseModel
from openai import OpenAI
class Step(BaseModel):
explanation: str
output: str
class MathResponse(BaseModel):
steps: list[Step]
final_answer: str
client = OpenAI()
completion = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system", "content": "You are a helpful math tutor."},
{"role": "user", "content": "solve 8x + 31 = 2"},
],
tools=[
openai.pydantic_function_tool(MathResponse),
],
# response_format=MathResponse,
)
message = completion.choices[0].message
if message.parsed:
print(message.parsed.steps)
print(message.parsed.final_answer)
else:
print(message.refusal)
好处
- Dynamically generating user interfaces based on the user’s intent
- Separating a final answer from supporting reasoning or additional commentary
- Extracting structured data from unstructured data
如何实现
- GPT-4o 特别训练以理解复杂的schemas (non-determinstic)
- 工程化方法 (deterministic)
Constrained Decoding / Constrained Sampling
OpenAI实现约束解码的技术路线:
JSON schemas -> CFG (context-free grammar) -> 结合语法规则和已有token来确定下一步的有效token -> 掩码下一步采样
为什么使用CFG:
- Finite State Machines (FSMs)
-
regexes (FSMs)
无法处理递归schemas
Structured Outputs takes inspiration from excellent work from the open source community: namely, the outlines(opens in a new window), jsonformer(opens in a new window), instructor(opens in a new window), guidance(opens in a new window), and lark(opens in a new window) libraries.
技术原理
解码技术
大模型能力提升的三驾马车:
- 训练微调
- 提示工程
- 解码策略
什么是语言模型解码
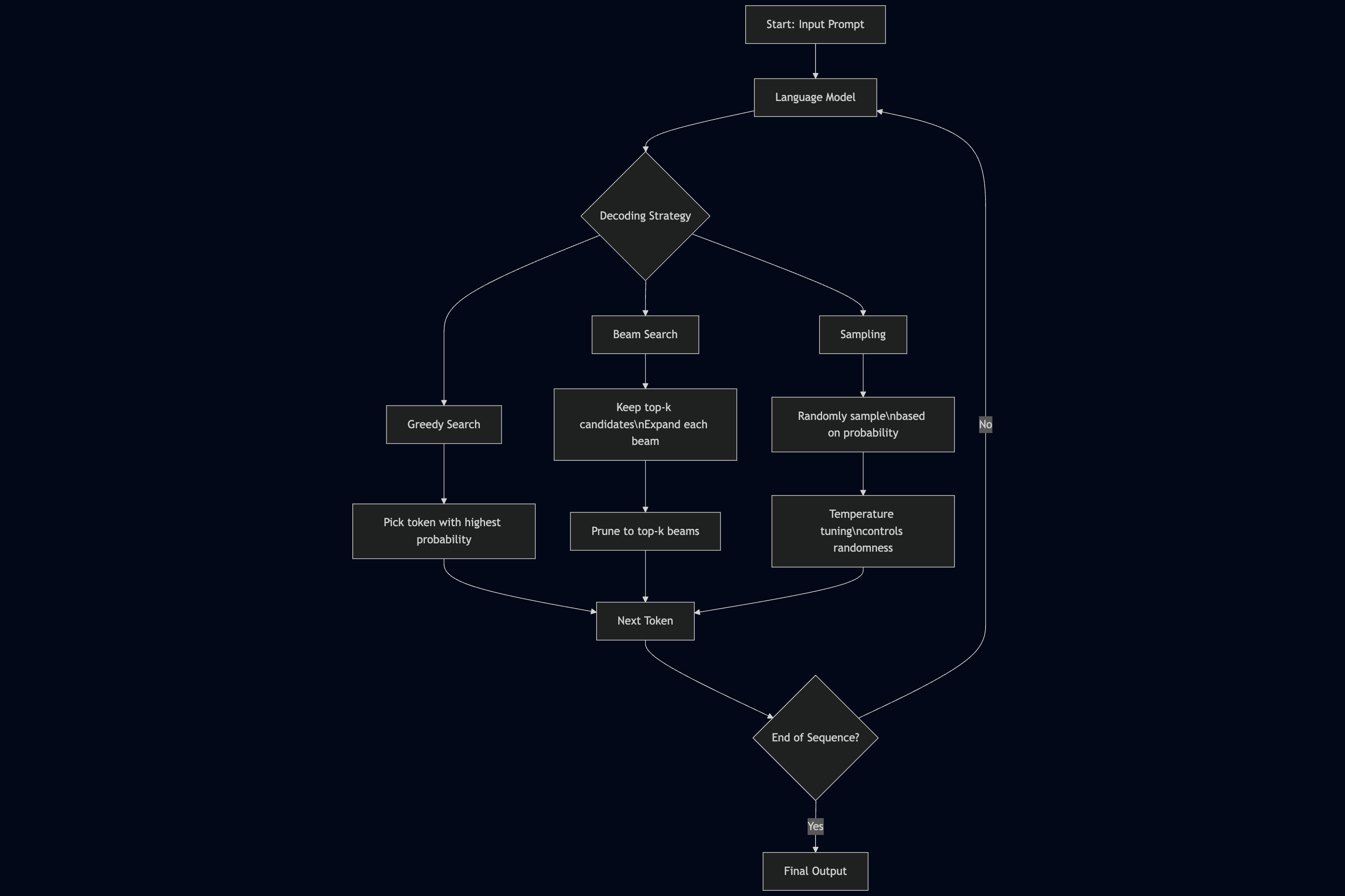
解码策略
最常用的几种解码方式
MAP (maximum a-posteriori) decoding
- Greedy Decoding
- (narrow) beam search (multiple prefixs) 问题: degeneration: short, repeatitive sequen
Stochastic methods
- Top-k sampling
- Top-p sampling (Nucleus sampling)
- Temperature sampling (0<t<1, 1, t>1)
参数设置
GenerationMixin
model.generate()
- GenerationConfig
- greedy decoding if num_beams=1 and do_sample=False
- contrastive search if penalty_alpha>0 and top_k>1
- multinomial sampling if num_beams=1 and do_sample=True
- beam-search decoding if num_beams>1 and do_sample=False
- beam-search multinomial sampling if num_beams>1 and do_sample=True
- diverse beam-search decoding if num_beams>1 and num_beam_groups>1
- constrained beam-search decoding if constraints!=None or force_words_ids!=None
- assisted decoding if assistant_model or prompt_lookup_num_tokens is passed to .generate()
- logits_processor
- LogitsProcessorList
- minLengthLogitsProcessor
- PepetitionPenaltyLogitsProcessor
- NoRepeatNGramLogitsProccesor
- LogitsProcessorList
- StoppingCriteria
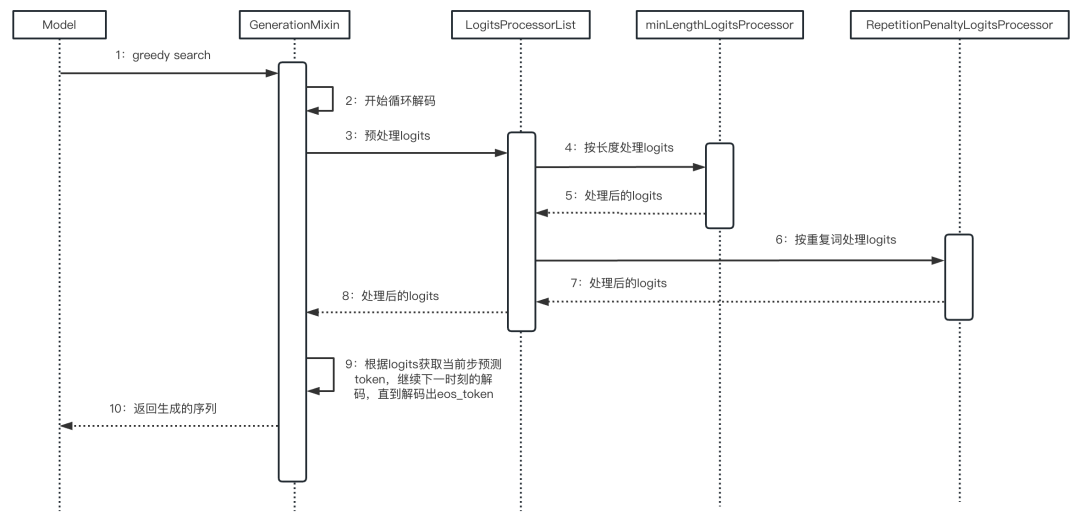
LogitsProcessor类是专门改变模型输出概率分布的工具
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, TextStreamer
from transformers.generation.logits_process import LogitsProcessor, LogitsProcessorList
from typing import List
import torch
class new_logits_processor(LogitsProcessor):
def __init__(self, forbid_token_id_list: List[int] = None):
self.forbid_token_id_list = forbid_token_id_list
def __call__(self, input_ids: torch>LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
for id_ in self,forbid_token_id_list:
scores{:, id_] = -float('inf')
return scores
pip install torch
pip install "transformers==4.24.0"
from transformers import AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer,from_pretrained('gpt2-large')
input_ids = tokenizer('DeepMind Company is' , return_tensor='pt').input_ids
model = GPT2LMHeadModel.from_pretrained('gpt2-large')
output = model.generate(input_ids, max_length=128)
print(tokenizer.decode(output[0], skip_special_tokens=True))
impoprt torch
form transformers import AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('gpt2-large'}
input_ids = tokenizer('DeepMind company is', return_tensor='pt').input_ids
model = GPT2LMHeadModel.from_pretrained('gpt2-large')
torch.manual_seed(0.)
output = model.generate(input_ids, do_sample=True, max_length=128, top_p=0.95, top_k=0)
print(tokenizer.decode(output[0], skip_special_tokens=True))
更高阶的解码方法
- Contrastive decoding / Contrastive search
- Speculative Sampling / assisted decoding
- DoLA
Contrastive Search 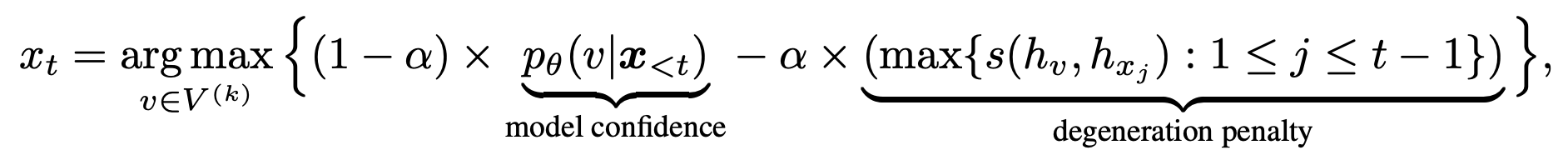
# Contrastive decoding
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model_name = 'gpt2-large'
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name, pad_token_id=tokenizer.eos_token_id)
model.eval()
input_ids = tokenizer('DeepMind company is', return_tensor='pt').input_ids
output = model.generate(input_ids, penalty_alpha=0.6, top_k=4, max_length=512)
print(tokenizer.decode(outputp[0], skip_special_tokens=True))
# assisted decoding
from transformers import AutoModelForCausalLM, AutoTokenizer
prompt = "Alice and Bob"
checkpoint = "google/gemma-2-9b"
assistant_checkpoint = "double7/vicuna-68m"
assistant_tokenizer = AutoTokenizer.from_pretrained(assistant_checkpoint)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
outputs = model.generate(**inputs, assistant_model=assistant_model, tokenizer=tokenizer, assistant_tokenizer=assistant_tokenizer)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
import torch
from accelerate.test_utils.testing import get_backend
tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-7b")
model = AutoModelForCausalLM.from_pretrained("huggyllama/llama-7b", torch_dtype=torch.float16)
device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
model.to(device)
set_seed(42)
text = "On what date was the Declaration of Independence officially signed?"
inputs = tokenizer(text, return_tensors="pt").to(device)
# vanilla greddy decoding
vanilla_output = model.generate(**inputs, do_sample=False, max_new_tokens=50)
tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
['\nThe Declaration of Independence was signed on July 4, 1776.\nWhat was the date of the signing of the Declaration of Independence?\nThe Declaration of Independence was signed on July 4,']
#DoLa decoding with contrasting higher part of layers
dola_high_output = model.generate(**inputs, do_sample=False, max_new_tokens=50, dola_layers='high')
tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
['\nJuly 4, 1776, when the Continental Congress voted to separate from Great Britain. The 56 delegates to the Continental Congress signed the Declaration on August 2, 1776.']
# DoLa decoding with contrasting specific layers
dola_custom_output = model.generate(**inputs, do_sample=False, max_new_tokens=50, dola_layers=[28,30], repetition_penalty=1.2)
tokenizer.batch_decode(dola_custom_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
['\nIt was officially signed on 2 August 1776, when 56 members of the Second Continental Congress, representing the original 13 American colonies, voted unanimously for the resolution for independence. The 2']
当前工作流
以OpenAI client为例
from openai import OpenAI
# initialize the client but point it to TGI
client = OpenAI(
base_url = "<ENDPOINT_URL>" + "/v1/",
api_key = "<HF_API_TOKEN>",
)
messages = [{"role": "user", "content": prompt}]
chat_comopletion = client.chat.completions.create(
model = "",
messages = messages,
stream = True,
max_tokens = 1024
)
message = chat_completion.choice[0].message.content
支持的参数:
- stream
- max_tokens
- frequency_penalty
- logprobs
- seed
- temperature
-
top_p
以上都是token-level的生成算法
搜索方法 (OpenAI o1)

- 多模型多提示组合
- 问题分解
- 并行解码 (自我一致性,多数投票,重排序,概率分布转移)
- TOT,GOT,MCTS
o3
- “program synthesis” for task adaptation
- natural language program search
- evaluator model: a new kind of reasoning
- executing its own programs
- deep learning guided program search
Constrained Decoding
开源工作
| Library | Feature |
|---|---|
| ggerganov/llama.cpp | contains a built-in support for CFG and supports JSON Schema through conversion to CFG |
| guidance-ai/guidance | CFG, Regex, JSON Schema, Token Forcing, compatible with Transformers, LLAMA-CPP |
| outlines-dev/outlines | CFG, Unicode support, Hugging Face ecosystem, VLLM support |
| sgl-project/sglang | Regex support, emphasis on LLM inference efficiency, compressed FSM |
| eth-sri/lmql | Regex support, various constraints, more powerful control flow |
| jxnl/instructor | Try-Reject-Repeat approach to ensure constraints are met |
| microsoft/aici | A general framework of LLM controller with native support for CFG, Regex, JSON Schema |
| noamgat/lm-format-enforcer | Regex, JSON Schema, Beam Search etc. |
| mlc-ai/xgrammar | CFG, careful system optimizations |
| epfl-dlab/transformers-CFG | CFG (EBNF Interface), Compatible with Transformers, Easy to extend for research |
| uiuc-focal-lab/syncode | CFG generation that supports builtin grammars like JSON, Python, Go, and more |
| r2d4/parserllm | Use context-free grammars with an LLM |
应用
- 有效的json格式
- 遵循正则表达式
- 遵循CFG语法
- 复杂提示,搜索
案例
- Knowledge Graph Generation
- ReAct Agent
- Extract data to CSV
案例一:使用有限状态机限制模型输出浮点数
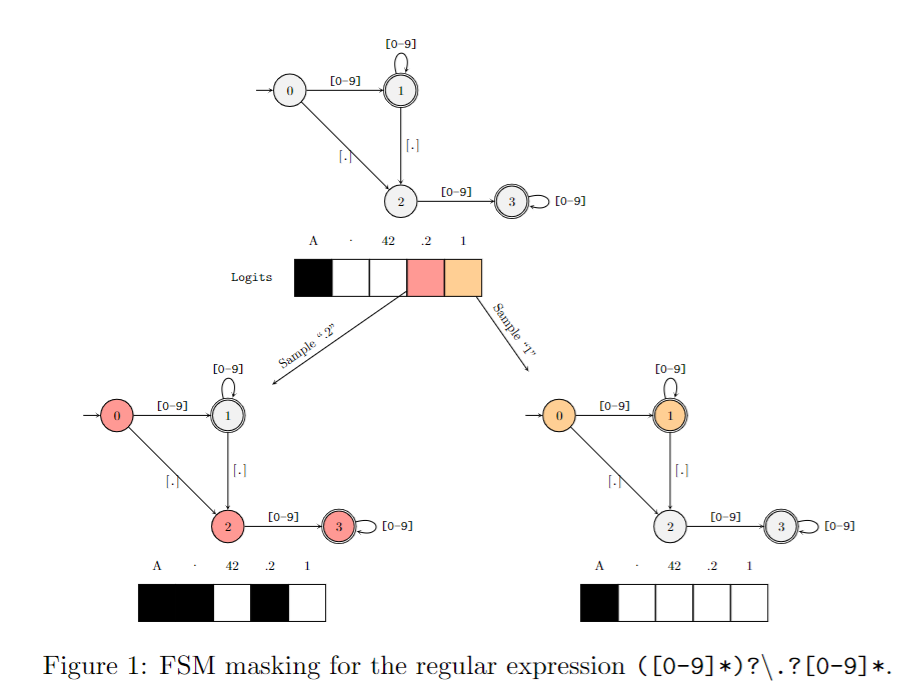
案例二:多项选择
import outlines
model = outlines.models.transformers("microsoft/Phi-3-mini-4k-instruct")
prompt = """You are a sentiment-labelling assistant.
Is the following review positive or negative?
Review: This restaurant is just awesome!
"""
generator = outlines.generate.choice(model, ["Positive", "Negative"])
answer = generator(prompt)
案例三:SQL生成
预期输出:
Translate the following question to SQL. “What is the age of a student called John Doe?” SELECT```
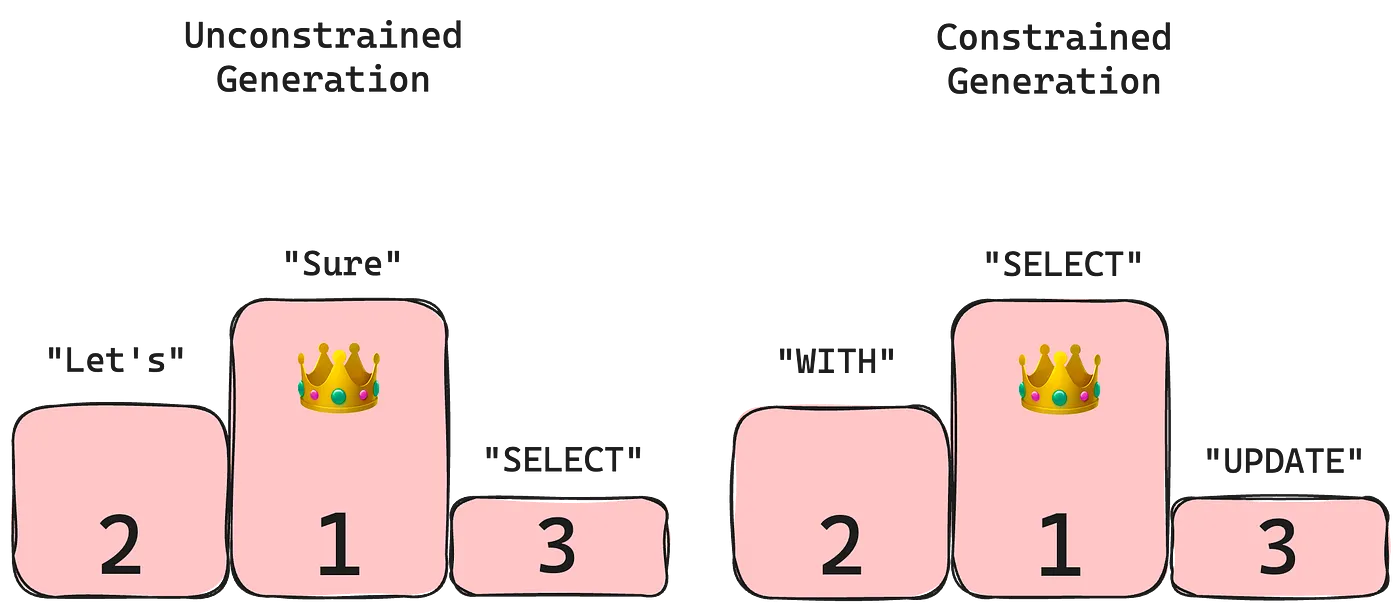
Simple SQL grammar 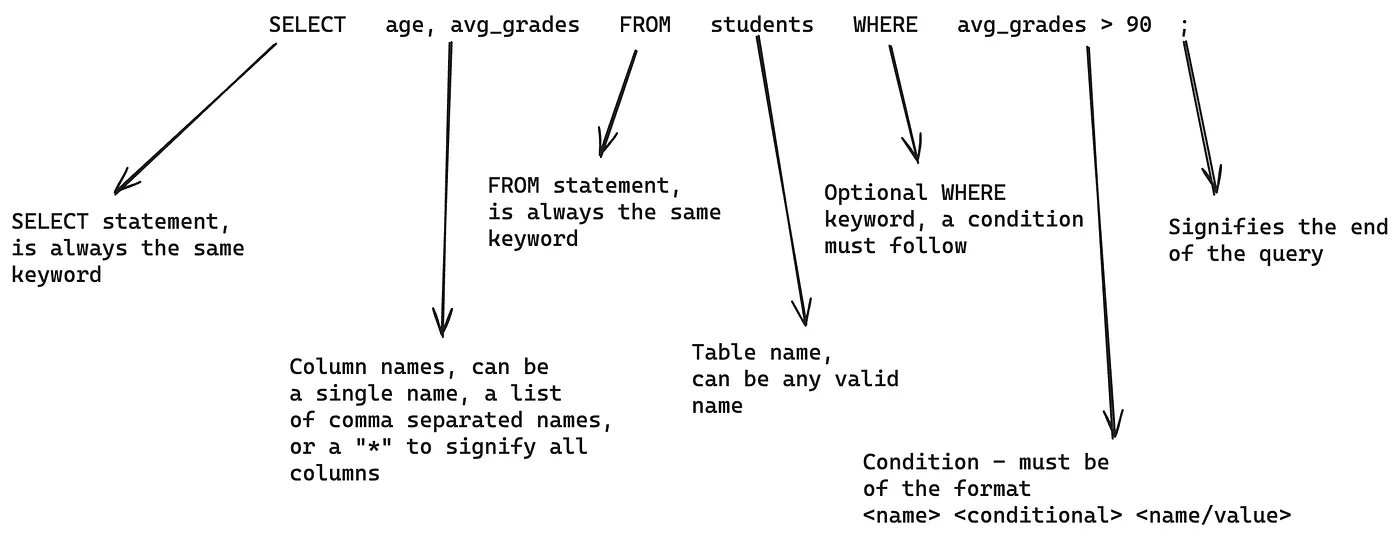
a lark context free grammar definition:
start: select
select: "SELECT " columns "FROM " table ("WHERE " condition)? ";"
columns: _columns " "
_columns: _column (("," | ", ") _column)* | "*"
_column: /([A-Za-z0-9]+)/
table: _table " "
_table: /[A-Za-z0-9]+/
condition: _first_term _comp_op _second_term
_comp_op: "=" | "!=" | "<" | ">" | "<=" | ">="
_first_term: /([A-Za-z0-9]+) */
_second_term: / *([A-Za-z0-9]+|'[^']*')/
使用该语法生成SQL:
pip install parserllm transformers lark
from lark import Lark
from parserllm import complete_cf
from transfomers import AutoModelForCausualLM, AutoTOkenizer
# define our grammar
select_grammar = """
start: select
select: "SELECT " columns "FROM " table ("WHERE " condition)? ";"
columns: _columns " "
_columns: _column (("," | ", ") _column)* | "*"
_column: /([A-Za-z0-9]+)/
table: _table " "
_table: /[A-Za-z0-9]+/
condition: _first_term _comp_op _second_term
_comp_op: "=" | "!=" | "<" | ">" | "<=" | ">="
_first_term: /([A-Za-z0-9]+) */
_second_term: / *([A-Za-z0-9]+|'[^']*')/
"""
# create the parser - see lark docs for arguments
sql_parser = Lark(grammar=select_grammar, regex=True, parser='lalr')
# get the model and appropriate tokenizer
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-2")
# define our prompt - this is a recommended format for phi-2
prompt = """Instruct: Can you translate the following question to SQL: \\"What is the age of a student called 'John Doe'?\\"
Output:"""
# generate a completion
completion = complete_cf(prompt, sql_parser, "", tokenizer, model, max_new_tokens=25)
print(completion)
SELECT age FROM student WHERE name= 'John Doe';
进一步地, 我们可以给语法添加表列信息:
start: select
select: "SELECT " columns "FROM " table ("WHERE " condition)? ";"
columns: _columns " "
_columns: _column (("," | ", ") _column)* | "*"
_column: "zip_code" | "years_since_born" | "name" | "eye_color"
table: _table " "
_table: /[A-Za-z0-9]+/
condition: _first_term _comp_op _second_term
_comp_op: "=" | "!=" | "<" | ">" | "<=" | ">="
_first_term: /([A-Za-z0-9]+) */
_second_term: / *([A-Za-z0-9]+|'[^']*')/
SELECT name,years_since_born FROM student WHERE name= 'John Doe';
案例四: ReAct状态信息与工具使用
@guidance
def react_prompt_example(lm, question, max_rounds=10):
lm += f'Question: {question}\n'
i = 1
while True:
lm += f'Thought {i}: ' + gen(suffix='\n')
lm += f'Act {i}: ' + select(['Search', 'Finish'], name='act')
lm += '[' + gen(name='arg', suffix=']') + '\n'
if lm['act'] == 'Finish' or i == max_rounds:
break
else:
lm += f'Observation {i}: ' + search(lm['arg']) + '\n'
i += 1
return lm
优势:
- 注入领域知识,模板和约束
- 提升解码速度
限制:
需要获取logits
自定义Logits
支持Structured output的开源大模型推理部署引擎
vLLM:支持outlines、xgrammar(in beta) SGLang:outlines, xgrammar
支持的参数: guided_choice: the output will be exactly one of the choices.
guided_regex: the output will follow the regex pattern.
guided_json: the output will follow the JSON schema.
guided_grammar: the output will follow the context free grammar.
guided_whitespace_pattern: used to override the default whitespace pattern for guided json decoding.
guided_decoding_backend: used to select the guided decoding backend to use.
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="-",
)
completion = client.chat.completions.create(
model="Qwen/Qwen2.5-3B-Instruct",
messages=[
{"role": "user", "content": "Classify this sentiment: vLLM is wonderful!"}
],
extra_body={"guided_choice": ["positive", "negative"]},
)
print(completion.choices[0].message.content)
参考文献
- “We Need Structured Output”: Towards User-centered Constraintson Large Language Model Output
- Large language models for generative information extraction: a survey
- Introducing Structured Outputs in the API
- A Thorough Examination of Decoding Methods in the Era of LLMs
- From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models
- A Survey on LLM Inference-Time Self-Improvement
- Awesome-LLM-Constrained-Decoding
- Efficient Guided Generation for Large Language Models
- Syntax Strategies: generating constrained SQL with LLMs
- 大语言模型控制生成的过程Trick:自定义LogitsProcessor实践
- Text generation strategies
- LLM结构化输出代码示例和原理分析
- Say What You Mean: A Response to ‘Let Me Speak Freely’
- XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models
Enjoy Reading This Article?
Here are some more articles you might like to read next: